Data Integration
-
Notification - Device not sending logs >24 hours
Hi Team,
How to setup “Device not sending logs “ alert in Logpoint and how to configure that alert to email like sftp setup.
Thanks
Satya
-
Tagging devices - criticality
Hi Team,
Can we tag the device criticality in logpoint,
We are looking to create notification for critical and high severity devices.
-
Normalizer Timestamp
I have a nice Logfile (FlatFile with once a day import via Ubuntu LogPoint Agent) containing a timestamp like:
| 20210905 | 231304 |
Any suggestions how i need to modify my Normalizer to understand this Time ?
Edit:
I do some sed Magic and change the Format directly in the Logfile
-
Multi line parser for Java applications.
Hi.
We are trying to push multi-line logs to Logpoint, for example a stack trace.
They are created by Java applications like Jboss, Tomcat and few more. Where we have some debug information in logs such as content of XML messages processes by the system etc.
When such logs are displayed in Logpoint, we need to preserve the line breaks along with indentation to make them readable by a human.
Can you please show a complete recipe on how to achieve that?
I saw this topic
https://community.logpoint.com/normalization-parsing-43/multi-line-parser-147
and understood that there are some pre-compiled normalizers which can be used, can you please explain how they gonna work and how exactly we need to:
1. send logs to Logpoint
2. process logs in logpointIn order to be able to present properly formatted (line breaks and indentation) logs for users who will look for the logs ?
Thanks
-
Problem adding McAfee ePo server via Syslog
We configured our McAfee ePO (5.10) server to send its logs to a syslog server and configured it in the LP accordingly. Yet, when using the “Test Syslog” Feature in McAfee ePO, the test failed. Nonetheless, we are receiving logs from the server, but they only contain gibberish.

LP raw logs This is as far as i think not a problem with normalization, as a tcpdump also shows the log payload not being human readable.

tcpdump I already tried to change the charset min the log m,collection policy from utf_8 to iso8559_15 and ascii, to no avail.
I found following McAfee ( KB87927 ) document, which says:
ePO syslog forwarding only supports the TCP protocol, and requires Transport Layer Security (TLS) . Specifically, it supports receivers following RFC 5424 and RFC 5425 , which is known as syslog-ng . You do not need to import the certificate used by the syslog receiver into ePO. As long as the certificate is valid, ePO accepts it. Self-signed certificates are supported and are commonly used for this purpose.
So my current guess it that the test connection failed as the ePO is expecting the LP to encrypt the traffic, which it does not do. Yet it still started to send the LP encrypted logs (but what cert does he use), therefore the gibberish.
Hence my question, did anyone manage to successfully retrieve usable logs from a McAfee ePO server using Syslog, or might have any suggestion what is wrong with my configuration ?
-
Debian Normalizers
I want to add some Linux Logs to Logpoint and I have seen that there are so many different normalizers that the testing would be take forever . . .
Has somebody a best practice normalizers for a default Debian rsyslog configuration?
-
Howto: Increase maximum size of syslog message
In the default configuration the syslog_collector process only accepts messages (log lines) with a maximum of 10000 bytes (characters). This results in truncated messages and thus they will not be normalized correctly. Especially powershell script blocks may contain important information, but generate very long log messages.
Unfortunately this is a fixed value in the syslog_collector binary.
At least the c code is avialable in the system and you can adjust the values and compile the binary again.For this you need sudo/root access.
sudo -i # become root
cd /opt/immune/installed/col/apps/collector_c/syslog_collector/
cp syslog_collector.h syslog_collector.h.bak # create a backup of the file
nano syslog_collector.hchange the value here in this line:
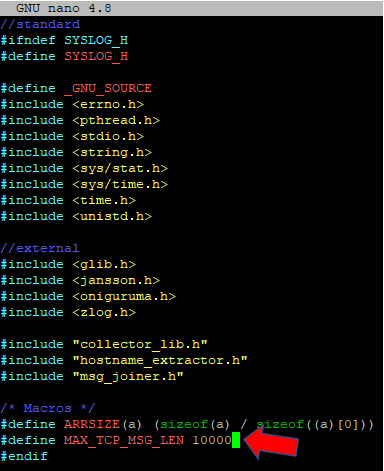
compile the syslog collector using:/opt/immune/bin/envdo make clean
/opt/immune/bin/envdo make
sv restart /opt/immune/etc/service/syslog_collector/ # restart the serviceIt would be a great feature to be able to set this value within the web UI.
-
Multi line parser?
Hi,
How do you create a “multi line” normaliser, e.g. Java logs (stack traces) or JSON objects?
-
Working with UDP on LPAgent
Hello all!
The docs portal https://docs.logpoint.com/docs/logpoint-agent/en/latest/Installing%20the%20Application.html mentions that we use TCP for communication between LPAgent and the Logpoint server. What can we do in case of UDP instead?
-
Time Searches
I have come across a query that ends up spitting out the month in text - I would have expected it to come out as a number, is that possible?
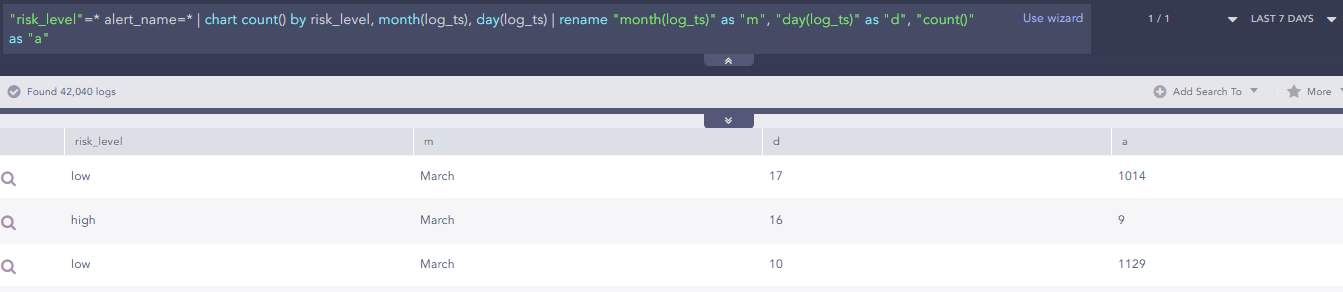
-
Normalizing Windows logs using nxlog agent
When using the nxlog agent for Windows (instead of the LogPoint Agent for Windows) how can I get the logs properly normalised?
-
Process to request a new log normalization support
Hi Team, My customer has a new network appliance that is not yet supported by LogPoint. What is the process to request its support ?
-
how to define a static field on a data source
Hi,
I need to define a static field on a data source, like ‘datacenter=Paris’. What is the best way to achieve that ?
Thanks
-
I want to add a field management_address to its respective device_address..
Hi,
I have a case where Analyst uses the management IP, however there is a NAT address on the client side. The device address configured in the logs provide client IPs.So I am looking to add a field management_address that we will define based on the device_address
ie: when an event has device_address=192.168.1.1 add field management_address=10.10.10.10I've looked into a few ways to do this. Enrichment source I didn't see a good way to go about it. Adding a custom normalizer would be possible, but would have to add a signature for every IP <:ALL>192.168.1.1<:ALL> and then add keyvalue management_address=10.10.10.10
Label package would also be do-able and easier than norm signatures, but that would put the new IP in a label, rather than within the normalized event.Wondering if anyone has come up with any other solutions or ideas.
-
Automatic Normalization
It would be great if there were some means to automatically select the respective normalizers automatically. This would reduce the implementation overhead and also help us select the best available normalizers. We could leave a process to analyze the logs and find the normalizers it requires at the start of the implementation and allow it some time to process.
What are the limitations/drawback for doing so?