SIEM - Architecture & Configuration
-
Running LogPoint as Docker Container
I just managed to run LogPoint as a docker image/container.
It is relatively simpel and could help improving testing systems, where you want to start from a fresh logpoint for each test, make the desired configurations, run the test and discard the changes at the end.
Our use case was developing a unit testing framework for alert rules.
- Spin up the docker container
- Configurate repo, routing policy, normalization policy, processing policy, device and syslog collector
- Configurate the alert rule to test (test object)
- Send some pre-defined logs via syslog to the docker-logpoint
- Wait pre-defined time to see if the behaviour of the alert rule is as expected (triggers or doesn’t trigger)
- Stop the docker container, discarding all changes (configuration, log storage, etc.)
- Repeat with the next test scenario
Here is what I did to run logpoint in a container. I did this on a linux machine (debian 12) with docker.io installed:
- Download latest OVA (here logpoint_7.4.0.ova)
-
Extract the OVA (which is a tarball at all)
-
tar xf logpoint_7.4.0.ova
-
-
Convert the VMDK disk image to a raw disk image with qemu-img
-
qemu-img convert -O raw LogPoint-7.4.0.vmdk LogPoint-7.4.0.raw
-
-
Figure out the start position of the LVM partition in the disk image
-
parted -s LogPoint-7.4.0.raw unit b print - Look for the start number of the 4th partition, copy it without the “B” at the end
-
-
Create a mountpoint where you mount the LVM partitions to
-
mkdir /mnt/rootfs
-
-
Create a loop device stating at the 4th partition postition we got from parted
-
losetup -o <START POSITION> -f LogPoint-7.4.0.raw
-
-
Mount the LVM LVs to our mountpoint
-
mount /dev/LogPoint-vg/root /mnt/rootfs/ -
mount /dev/LogPoint-vg/application /mnt/rootfs/opt/ -
mount /dev/LogPoint-vg/app_store /mnt/rootfs/opt/makalu/app_store/ -
mount /dev/LogPoint-vg/storage /mnt/rootfs/opt/makalu/storage/
-
-
Compress the whole filesystem into a gzip compress tarball for docker import
-
tar -czf image.tar.gz -C /mnt/rootfs/ .
-
-
Import the tarball as docker image
-
docker import image.tar.gz logpoint:7.4.0
-
-
Get the new logpoint docker image ID
-
docker images
-
-
Spin up a container and run an interactive shell inside the container
-
docker run --security-opt seccomp=unconfined --privileged --ulimit core=0 --ulimit data=-1 --ulimit fsize=-1 --ulimit sigpending=62793 --ulimit memlock=65536 --ulimit rss=-1 --ulimit nofile=50000 --ulimit msgqueue=819200 --ulimit rtprio=0 --ulimit nproc=-1 -p 8443:443 -p 8514:514 -p 822:22 -i -t <IMAGE ID> /bin/bash
-
-
Switch to the new less memory consuming shenandoah Java GC
-
sudo -u li-admin /opt/immune/bin/li-admin/shenandoah_manager.sh enable
-
-
Start the logpoint processes
-
/opt/logpoint/embedded/bin/runsvdir-start
-
I hope this helps some of you!
-
【Japanese language support】We can provide/support Japanease language menu
Dear Team,
Since we need to prepare Japanese Web UI we want to provide it then please incorporate into your source code.
Japan’s market is really needed to support our own language.
Kindly understand our situation and cooperate with it.
Could you do that?
regards,
Yoshihiro
-
Has anyone tried getting log data from Topdesk in paticulare auditdata
This is a cloud services and looking for a solution to get data to our onprem LP servers.
Regards Kai
-
Logpoint 7.3.0 upgrade stalled
I have uploaded the logpoint 7.3.0 and 7.3.1 pak on logpoint server 7.2.4.
I have started the 7.3.0 pak installation but after some hours is still in “installing” state
Checking the status I see that is blocked on SOAR Plugin upgrade
………
…………...
Checking package status ...
install; giving etc/, storage/ and var/ to loginspect only in changed files
install; removing old files
install; copying files
Update; updating plugins....
Upgrading SOAR pluginI tried to install the 7.3.1 pak that fails because the 7.3.0 is not installed.

I have restarted the server but nothing change.
Could you please help me to understand the cause?
-
Newbie: Distributed Logpoint
hello guys, good day
newbie here and I am taking overed from our previous employee. correct me if I’m wrong since it is still in final design
I need to deploy distributed LP in customer environment, we provide them 2 ESXi and this is our 1st customer migrated from Microfocus. The components are: (current)
- search head x1
- distributed logpoint x1
- log collector x2 (collect log for on-prem x1, collect log for cloud but sitting on prem)
for windows, planning to use LPA and the rest syslog
Issue 1:
I do some testing and I realized all the API or Cloud Trail configuration directly into DLP. Reason I am thinking, we do not need the LC on this case and the pros is we have the opportunity to turn on SOAR features also increase the specification/storage for DLP.
Do I need to turn on this DLP as collector also?
Issue 2:
license: 325 nodes (300 servers/security/network and 5 API: sophos, office365 and 1: AWS cloud trail)
I believed 325 nodes will be installed inside the DLP and but not sure about SH and LC, I think I need to purchase another 3 licenses for the rest so new licenses are 328 nodes. Any advise?
Issue: 3
based on my study/reading info, the LC is a collector also function as normalizer log.
in my case, when the LC act a normalizer? because:- after turn on collector, there is no dashboard etc
- eg: LPA, the configuration for normalizer at the DLP not inside the LC
Thanks for your response.
Regards,
Mohamed
-
Logpoint Health monitoring through Grafana
Hi All,
We do have different clients and we want to create a real time monitoring system.
Is it possible to integrate it on Grafana, if yes do you have any idea how?
i know that monitoring through email is possible but we want a centralized monitoring system
Thanks
-
LogPoint [AIO] - import syslog from a syslog server
Hello,
I have an archive server were I store some syslog/json logs on. I wonder If It’s possible to send over som of these to LogPoint?
Is It possible manually to transfer over some of the logs from the archive → Logpoint AIO? Like use scp or something else.
I dont find any related documentation related to this. -
Sylog message sizing
Hi
What are your opinions on increasing the size of the syslog message.
Increasing syslog message size will potentially have a negative impact on the performance in log collection, normalization and parsing.
On the other hand it is important to be able to extract the necessary information from collected log messages, and some windows evenLog messages have increased over time.
Take for example event ID 4662 ‘An operation was performed on an object’, it can exceed 34000 in message size.
Another example is custom application logs, where developers might have another opinion, of what meaningful logs should contain.
Regards
Hans
-
Collector not pushing to data node
Hi,
I have a distributed system with dedicated collectors. Now, during setup and configuring a few hundred linux servers via rsyslog to send their logs to one collector, the collector suddenly stopped pushing the data further to the data node. I’ve rebooted the collector, which resulted in temporary relief, however after roughly two hours, the problem resurfaced.
Using tcpdump on the collector I can see logs streaming in from the log sources (tcp/514), and also on the data node I see openvpn-udp traffic comming in from the IP of the collector - not sure however if in latter I see only tunnel keepalive traffic, as the packages are very small 65-103 byte.
I don’t have a clue on how to understand what is going on and where to look at - seems some resource problem to me, in terms of memory or cpu the system is well equipped and bored :-).
The thing is, when doing a search over all repos with "collected_at"="myCollectorName" I don’t get any data at all. As if the thing would not exist.
Do you have ideas how to analyze this better?
Thx,
Peter
-
New Logpoint 7.2.0 is ready
The 7.2.0 version is out. Read about it here: https://servicedesk.logpoint.com/hc/en-us/articles/10065818192669-Logpoint-v7-2-0 .
During April, Logpoint will host a Webinar giving more insights into the new features. Look for it in your e-mail inbox or here on the Community
/ Brian Hansen, Logpoint
-
New Ideas in Ideas Portal
Hello together!
I hope you all look regularly in the idea portal?I have submitted some ideas that I wanted to draw attention to here:
-
Separate SOAR from SIEM Installation- and Update Packages
The update and installation packages have grown in size a lot since SOAR was introduced. The idea asks to un-bundle the SOAR package so that you don’t have to transfer and install 1.5 GB of update package, while the SOAR uses 1.4 GB of it. -
Preselect Dropdown Values if there is only one option
In the UI there are some dropdowns where usually you have only one selection option. If so, this should be preselected, so you can save some click-work. -
Implement Overview for Live Searches
It would be helpful to know how fast the responses of the live searches in your system are available to estimate which live searches can be optimized or consume the most resources. -
Director: Add configuration object overview and filtering
In the Director Console UI we need a better overview of all available configuration objects. My idea: Show everything (all devices, policies, etc.) in one table and add some filtering options so you can filter pool, machine, object type (device, policy,...). -
Director: Show all relevant information of devices in one simple overview
The device listing so that all relevant information about a device is visible at a glance. If a device has several values in some fields (e.g. several collector apps), then these should be displayed in several table rows or in a different but clear way. -
Director API for Director SSH Commands
It would be good if it was possible to run SSH commands on specific pools and machines via the Director API.
Feel free to add more of your Ideas here. Maybe we can start a discussion here about interesting topics.
-
Separate SOAR from SIEM Installation- and Update Packages
-
Custom Layout Template in search Master?
Trying to create a custom layout template for a report for a client using the LPSM but unable to.
-
Excel Exports contain HTML encoding - How to avoid?
When exporting to Excel the field ‘msg’ contains the same HTML encoding as the GUI.
This is how some example data are shown in the GUI:

This is how the Excel Speadsheet looks like for the same data:

This is the sourcecode for the tabel in the GUI, which shows that it contain the same html <span> tags:

Is it possible to get the Excel Export without html encoding in the msg field?
Perhaps it could be an option to enable/disable html <tags> in exports in the preferences menu?
-
Universal Normalizer
Think this is good news that should incite more people to take on the task of creating their own normalization package
https://servicedesk.logpoint.com/hc/en-us/articles/8874831748253-Universal-Normalizer
-
SAML Authentication v.6.0.1 is now available on the Logpoint Help Center
Dear all,
The newest version of the SAML authentication application enabling users to log into LogPoint using the SAML Identity Providers (IdPs) is now publicly released on the Logpoint Help Center. For more information and downloading instructions, please visit the link below.
https://servicedesk.logpoint.com/hc/en-us/articles/360002185778
-
Incident Management - Is it possible to automatically close cases ?
For our customer we currently have several alerts implemented. The customer has a rather small security team only interested in receiving email notification whenever an incident is triggered. So, the build in management incident of LogPoint is not used and all and i delete all open cases on a regular basis.
However, for auditing reasons, for some incidents posing a major risk they would now like the security personal to use the incident management system by LogPoint and want them to resolve the cases there. All other incidents should, if possible, not be visible to them.
Right now, i would assign these high risk alerts to the security personal so that are able to read and resolve them within LogPoint. Incidents with a lower risk would be assigned to me or a dummy group, and i would continue to regularly delete them manually.
But i am wondering whether there is a better way: Does triggering an alert automatically have to create an incident, or is it possible to configure that only alerts with a specific risk level create incidents ?
Also, is there a way to automatically close and resolve open incidents so i do not have to do this manually anmore.
Regards
Andre
-
Merge Repos
Hi all,
we started using LogPoint and created repos for every device type. Now that we have 20+ repos i want to optimize this process and group devices by functionality (e.g. email, remote access). So my intention is to create an new repo for every functionality and modify the routing policies. I think this should work but there is a great time span where i have to search in the “new” and the “old” repo because of retention times of 90 or more days.
Is there a smart way to copy the content from one repo to another so that i can get the optimizing done in a short time and this will not take 90+ days?
Best
edgar -
Support Connection GDPR compliance
Hi,
can anyone point me to terms & conditions describing compliance with GDPR regarding LogPoint support access using Support Connection functionality in LogPoint & Director? Or description what data can be accessible by support?
Best Regards,
Piotr
-
Logpoint collector behind NAT
Hi Community,
We have a distributed collector in a remote location. We have established a Site-to-site VPN between locations. The scenario is that the IP Address of the collector is in NAT and mapped to a different IP than that of the actual host IP.
For E.g the system IP of collector is 172.29.20.80 and the IP of the collector as seen by the Remote Logpoint is 172.22.2.2.
We have made the necessary configuration and ensured the Collector is visible in the logpoint. However, the IP as recorded by Logpoint is the actual system IP (Not the IP Logpoint should recognize it as). The issue is the status is Inactive stage.
Is this due to the difference in host IP and NAT address?
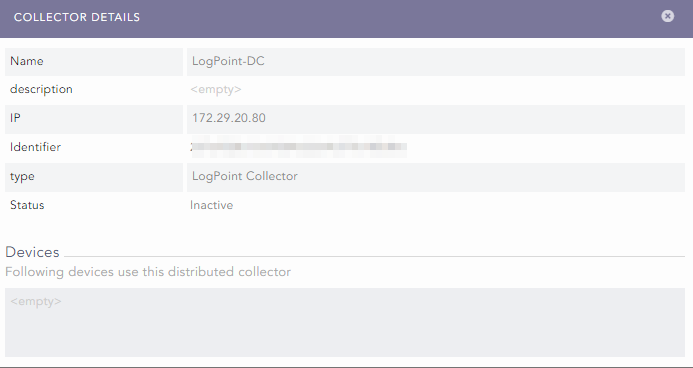
-
Qualys vulnerability management integration
Hello,
We’re looking at integrating our Qualys VM scans into our Logpoint instance. I was hoping to pick someone's brain about this. Does this only work on singular Qualys accounts, or will it work on MSSP/Consultant editions?
Many thanks,
-
LogPoint SIEM HDFS support and configuration
Hi,
does Logpoint support HDFS do store data e.g. on an DELL ECS object storage?
If yes, how must this be configured in best practice?
Thanks.
Best Regards,
Johann
-
max amount of Repos
Hello Guys,
is it possible to use/create 16 repositories per LogPoint environment only?
What if I like to separate my data in 30 different repositories for managment and access right purposes, is there a way to do that and are there benefits or drawbacks for this situation?
Thanks in advance.
BR,
Sascha
-
New in KB: How to use NFS storage as backup directory?
Hi All,
We are excited to share a new knowledge base article guiding you through the steps on how to use NFS storage as backup directory. You can access through the following link. https://servicedesk.logpoint.com/hc/en-us/articles/5068106299805-How-to-use-NFS-storage-as-backup-directory-
-
Microsoft Defender ATP v5.1.0 is now released
Dear all,
Microsoft Defender ATP v5.1.0 is now released and publicly available on the Help Centre via the link below:
https://servicedesk.logpoint.com/hc/en-us/articles/360007378817
-
SSL certificates for Web Interface with 1x Root CA and 2x Intermediaries
Hi folks,
We’re hoping to add some SSL certificates to our LogPoint installation for the web interface, but just wanted to clarify some information. We currently have SSL certificates with a Root CA and 2 intermediaries - do these need to be combined into a fullchain certificate, or does each part need to be put somewhere else in the LogPoint installation?
I saw this post with a reply from Nils referencing the CSR, which is great, but we just want to make sure that we’re putting the certificates in the right place.
If the certificate files do need to go somewhere else, I’m assuming they can’t be uploaded via the web interface?
-
Backup best practices
Hello,
I’m designing my backup. So far in the documentation, I’ve read two options: application snapshot and application backup, both are writing to the local disk.
Let’s put aside the configuration backup as it’s less than 1 GB. The real challenge comes with backing up repos.
In an on-prem infrastructure, backups are stored in the backup infrastructure, with VTL and so on. There’s no way I can request to double the size of the repo disk just to store a consistent backup that I will have, then, to transfer to the backup infrastructure.
In a cloud infrastructure, the backup would go directly to the object storage such as S3 Glacier. Neither would we rent a disk space used only during backup, though it might be easier to do in a cloud environment.
In addition to the backup and snapshot methods from the documentation, I should add the option of disk snapshot, either from the guest OS or from the disk array (only for on-prem infrastructure). These would provide a stable file system onto which the backup software must run (as snapshots are not backups). There is also the option to snapshot the entire appliance from the hypervisor and hope for the best.
Now, let’s say I’ve got 30 TB of logs I need to backup, which accounts for about one year of logs.
When I look at the documentation options, I would have to schedule a daily backup with the last day of data (but it doesn’t seem dynamic in the options), which would copy the files under /opt/makalu/backup/repos I assume, and then use SFTP to fetch these and find a way to inject them in the backup software. That doesn’t seem convenient at all.
We need to add to the previous thoughts the restoration use cases:
- The deletion of repo data by fucking up the retention configuration (I think it’s not possible to delete a repo that contains data)
- A corruption of the filesystem or destruction of the appliance
In case 1, we’d need to restore only a repo. In case 2, we need to restore everything.
When I look at the filesystem under /opt/makalu/storage, it looks neatly organised by year, month and day folder, then we’ve got unix timestamp filenames with in .gz (which triggers another question about the use of ZFS compression if the files are gzipped anyway). So, for case 1, if I could restore the appropriate folders of lost past data, I should be good. For case 2, if I restore the entire filesystem, I should be as good as possible. Maybe the filesystem won’t have the last commit on disk, but it shouldn’t be corrupted.
So, why is there all this backup thing in place that duplicates data locally for log repos? What am I missing that could just prevent good restoration if I backup the filesystem (that the hypervisor backup software should be able to quiesce externally and backup)?
Would the following be consistent?
- Run the configuration backup with LP job (because it looks like there’s a database and so on)
- Get the hypervisor to tell the guest OS to quiesce the filesystem, then snapshot the disks
- Backup the disks with whatever differential backup the backup software can do
Of course, it’s unlikely sysadmins will want to backup the 30 TB logs every day, because I predict the deduplication on an encrypted filesystem won’t be good (ha, I didn’t say but for regulation compliance the repos are encrypted by ZFS). Still, it could be a valid scenario.
How do customers backup large volume of logs?
-
Ideas: How to automatically (unit) test alert rules?
We use a large and growing number of self-developed alert rules for our customers, which we manage and develop further in an internal git repository via gitlab. For quality assurance in the continuous integration process, we still need a way to test the alert rules automatically.
The idea is to check whether each alert rule triggers on the necessary events and behaves as expected in borderline cases. Very similar to unit testing in software development, just for alert rules instead of source code.
Our idea so far is as follows:
- Connect an up-to-date LogPoint as a virtual machine as a QA system to our Director environment
- Create a snapshot of the "freshly installed" state
- Restore the snapshot via script from the gitlab CI pipeline
- Use the Director API to add a repo, routing policy, normalizer policy, processing policy for the different log types
- Use the Director API to add a device and syslog collector with the corresponding processing policy for each log type
- Use the Director API with our deployment script to deploy all alert rules
- For each alert rule, there is then a formal test specification that uses another script to send predefined log events with current timestamps to the logpoint system and check them against the expected triggering behavior of the enabled alert rules in the specification
- The CI pipeline status is set to "passed" or "failed" accordingly
Are there any ready-made approaches here, or recommendations on how to implement the above?
-
High Availability Repos usage
While deploying LogPoint with High Availability repos I did a few tests scenarios on how HA behaves that I thought would be relevant to share.
Repositories can be configured as high availability repositories which means that the data is replicated to another instance. This means that logs will be searchable in a couple of scenarios:First scenario, if the repo fails on the primary datanode (LP DN1) it will be able to search in the HA Repo_1 on the secondary datanode (LP DN2). This could for instance be that the disk was faulty or removed or the permissions on the path were set incorrect. This scenario can be seen in the picture below where the Repo 1 which is configured with HA, on the primary datanode (LP DN1) is unavailable, but still searchable as the secondary data node (LP DN2) still has the data in the HA Repo 1 repo. In this scenario the Repo 2 and Repo 3 are still searchable.
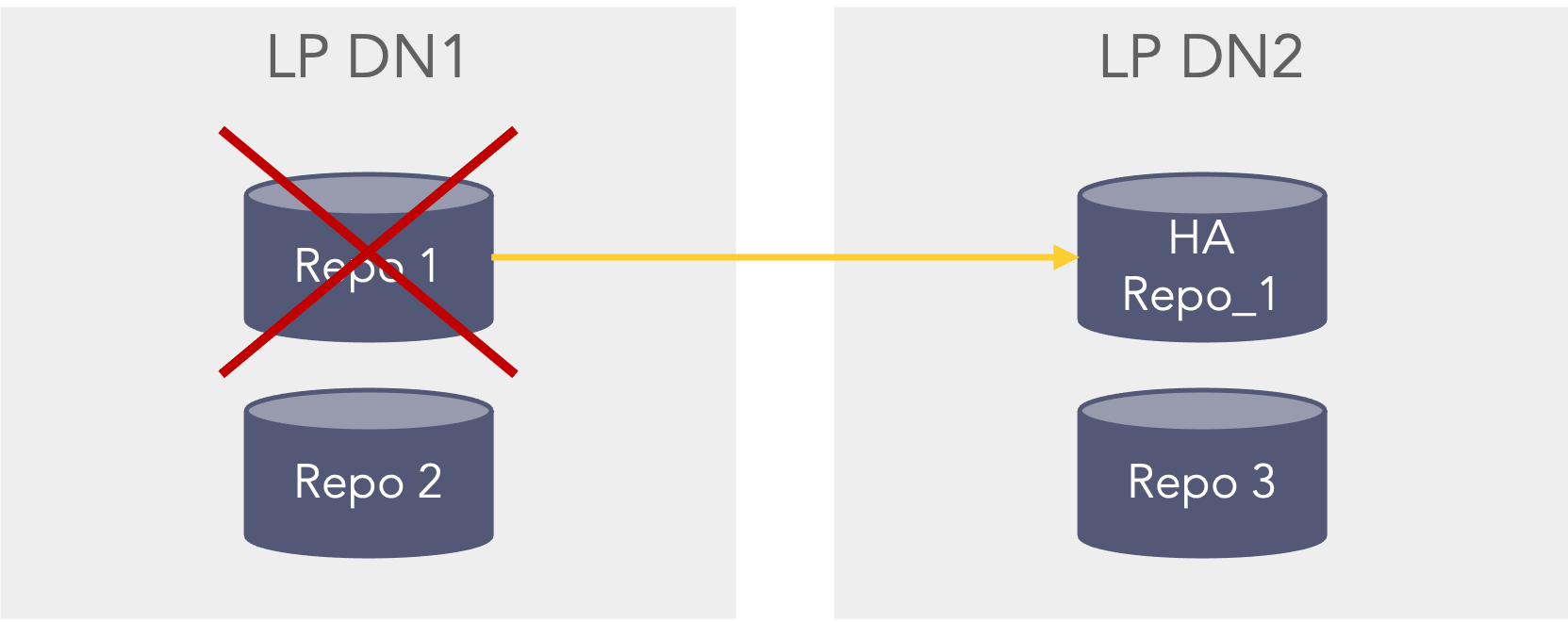
First HA scenario where one HA repo fails In the second scenario If the primary data node (LP DN1) is shutdown or unavailable the data can be searched from the secondary datanode (LP DN2). However, this can only happen if the primary datanode (LP DN1) is configured as a remote LogPoint on the secondary datanode (LP DN2), so that when selecting repo’s in the search bar the repo’s from the primary datanode (LP DN1) can be seen and selected when searching (This also applies before the primary datanode is down/unavailable) from the secondary data node (LP DN2). The premerger will then know that it can search on the HA repo’s stored on the secondary data node (LP DN2) even though the repo’s are down on the primary data node (LP DN1) as it cannot be reached. In this case the Repo 1 can be searched via the HA Repo 1 and the Repo 3 can also be searched, Repo 2 is not searchable.
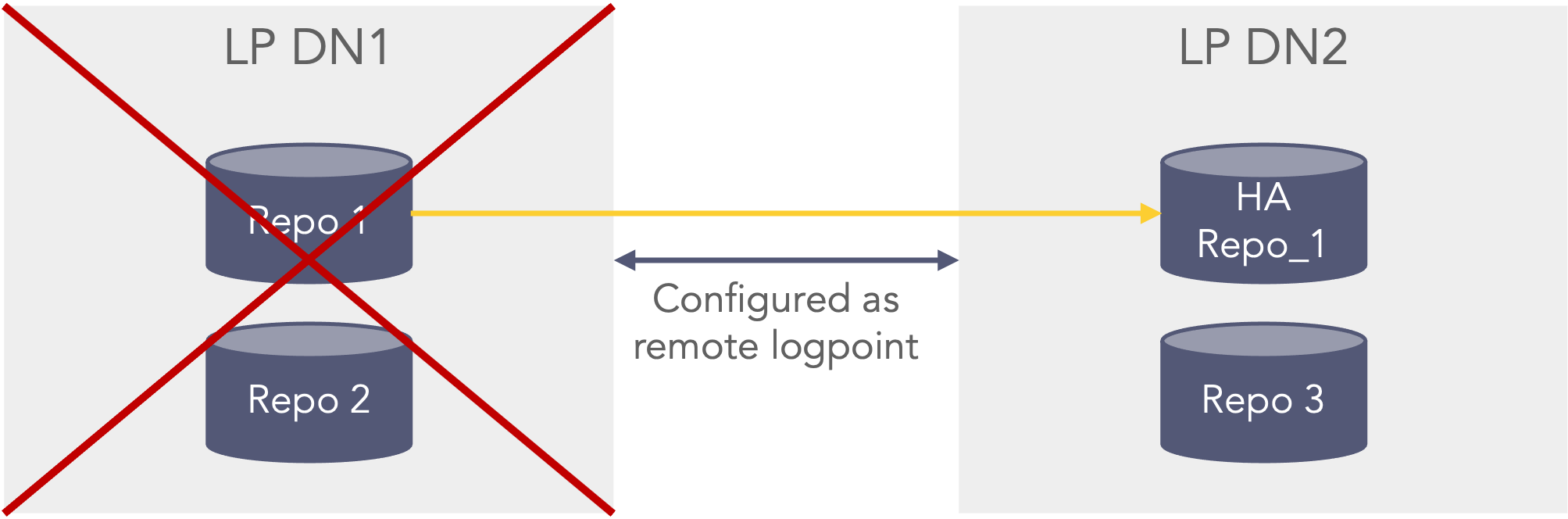
Second HA scenario where the full primary server is down or unavailable -
After update to 7.0 TimeChart does not work anymore
Be aware if your are going to upgrade to 7.0 there are a bug in TimeChart function, and will not work.
Answer from support:
Hi Kai,
We are extremely sorry for the inconvience caused by it, fixes has been applied in upcoming patch for 7.0.1So if you need it, maybe you should wait to 7.0.1 are out.
Regards Kai
-
LogPoint 7.0 is available now!
We are excited to announce that today we have released LogPoint 7.0.
With LogPoint 7, SOAR is a native part of the SIEM, which means getting one out-of-the-box tool for the entire detection, investigation and response process.
To learn more about LogPoint 7.0, access product documentation here: https://docs.logpoint.com/docs/install-and-upgrade-guide/en/latest/ or read our official press release here: https://www.logpoint.com/en/product-releases/streamline-security-operations-with-logpoint-7/
Should you have any specific 7.0 questions, post it in the Community and we will do our best to address it asap :)